Well, here’s what we’ve managed to pull together over the last six months. Many thanks to freelance developers, Eddie Tejeda and Alex Bilbie who developed the WordPress plugins and theme which we discuss below. [This post was written by Joss with help from Tony].
In our original bid, we proposed a ‘prototype demonstrator platform’ for JISC’s Funding Calls and Final Project Reports. We outlined 11 deliverables:
- A WordPress Multi-User based platform for authoring and publishing JISC funding calls in a form that allows paragraph-level comment and discussion either locally or remotely.
- A meta-site that aggregates all document data into a single site for search, navigation by categories and tags and can syndicate searches, tags and categories.
- Develop CommentPress to meet WCAG 2.0 accessibility guidelines, meeting public sector requirements.
- Evaluation and integration of “related content” utilities to dynamically link related project calls and reports based on content and/or semantic analysis.
- Evaluation and possible integration of remote, realtime messaging services such as Twitter and XMPP integration.
- Evaluation and possible integration of enterprise authentication services such as LDAP and Shibboleth.
- Evaluation and possible integration of OpenCalais, a semantic tagging service.
- Documentation on how to exploit the benefits of AWS and clone the project instance for other uses.
- A documented suggested workflow for document authors
- Documented examples of how to fully exploit the platform for data extraction and syndication.
- Documented ‘user stories’ for the JISC funding call process. Note that we do not guarantee fulfillment of all user stories.
I’ll go through each of these one by one with illustrations where relevant. A more informal reflection is also available (Thoughts on JISCPress ):
Paragraph level commenting and discussion of JISC funding calls
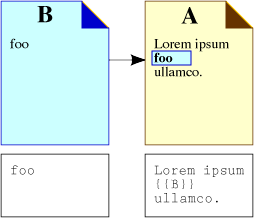
This was achieved through the development of the digress.it plugin. digress.it is a rewrite of the original CommentPress WordPress theme which we used on WriteToReply (which JISCPress is based on). I’ve posted a video interview with Eddie Tejeda, developer of the original CommentPress and digress.it, where he discusses the move from CommentPress to digress.it. In terms of local and remote paragraph commenting, the same feature set found in CommentPress has been retained. Remote, document section level comments are possible through the use of trackbacks.
We spent quite some time looking at remote paragraph level remote commenting and Eddie expects to support this with digress.it in the near future. We discovered that the use of trackbacks and pingbacks is an unreliable method of guaranteeing ‘comments’ from remote websites. It depends on the CMS being used and the settings of both the remote and local site. Sometimes, test comments we made never arrived, other times they did. So for example, whilst internal links within a WordPress domain may be recognised by other sites on the same platform, links from posts on other blogging platforms may not be. Link tracking using third party services (e.g. Google, Google blogsearch, BackType) rely on links being hardcoded in third party web pages (rather than being added dynamically to a page via Javascript, or within an embed object) and even then are not detected reliably (it depends on the crawler). Commercial tracking/monitoring services were not explored.
WordPress provides a robust commenting system, with excellent spam filtering and comment moderation features. digress.it leverages this locally to allow commenters to respond at the paragraph, rather than the section (i.e. blog post) level. For more on digress.it, Eddie talks in length about his work in a previously posted video interview.

An aggregated meta-site
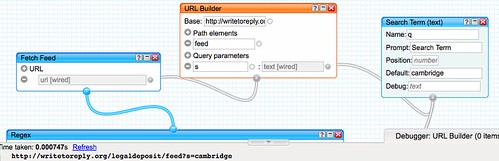
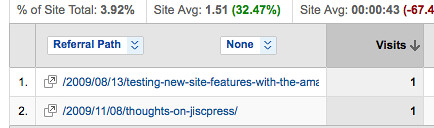
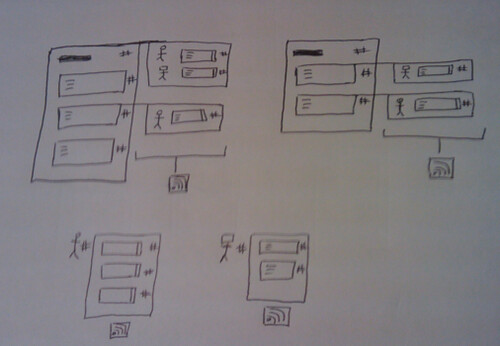
Alex has been working on this, which can be seen in the screenshot below (and until we take the server down, can be browsed at http://jiscpress.org )

What you see here are a number of ways of finding documents on the site. The large tag cloud uses tags generated from Alex’s Open Calais/Yahoo Term Extractor related tags plugin. This plugin uses both these third-party APIs to tag each document and then create intelligent relationships between documents on the site. More on that later. The tags are held in a separate database table to the human created, native WordPress tags, but are equally a source of information that can be used by theme designers and plugin authors. Here the tags are simply being used to display a cloud, similar to the one on http://en.wordpress.com/tags/ and marked up with the rel=”tag” microformat.
Clicking a tag lists the documents by title

As you can see, each result for a tag has an RSS feed, which can be found at the top right of the results. So if you’re interested in watching for key words in JISC documents, this would be a useful way of doing that. RSS feds can be monitored from feed readers such as Google Reader, or via web desktops, such as Netvibes (e.g. An Example Netvibes Dashboard). You don’t have to use the tag cloud to do that. You can construct your own and wait for the results to come in. i.e. http://jiscpress.org/?jiscpress_tag=MY_KEYWORD&feed
(Note that WordPress also offers the option of subscribing to a free text search using the default WordPress search utility, e.g. http://jiscpress.dev.lincoln.ac.uk/feed/?s=jiscpress )
Similarly, you can do this with ‘Topics’ (otherwise known as WordPress categories), which are aggregated from across all documents and displayed on the right side of the home page. For JISC’s purposes, there is a controlled list of about 40 Topics that are used by the organisation. Our example shows the use of a few of those. Again, if you’re interested in Funding Calls for Data & Text Mining, then you can subscribe to a feed for that Topic.
The main thing to point out about the use of WordPress categories on the Home Page, is that it assumes a controlled list and not a publishing environment where authors make up their own taxonomy. The list would get very very long and unmanageable. It need not use JISC’s Topics. Their Themes and Programmes would also work.
You’ll see that it displays the document title and author’s name. The use of author’s names is worth considering too. While WordPress is a multi-user CMS, it may be that each Programme decides to publish under their Programme’s name rather than the individual’s name. This is just a matter of changing the settings in WordPress, so that all the IE Team publish under their Programme’s name. The choice is up to JISC.
Above the ‘Topics’, is a list of the latest funding calls. It’s just a text box which some HTML links pointing to the latest documents. Nothing fancy nor difficult to maintain either.
In the backend, Alex has provided some options for the Tag Cloud (otherwise known as the JISCPress Browser widget). You can see that we have the option of using User, Open Calais and Yahoo tags, as well as blacklisting the display of certain tags, too. You can also decide how many tags you want to display.

The Topics are listed using a simple WPMU Site-wide categories widget that Alex wrote. It looks at the categories across all documents/blogs and displays them in alphabetical order.
For searching, we’re using the built in BuddyPress search (did I mention we’re using BuddyPress?). It simply allows you to search document titles from the front page or, on the Authors page, you can search authors by name, too.
Each Author has a profile page.

We looked at full-text search and it’s quite possible using this lucene-based plugin, which indexes all document text and all comments, too. It could be integrated into the theme to allow site-wide full text search but we chose not to because of time constraints and are simply using the built-in BuddyPress search. If JISC would like full-text search, it’s something that Alex could do. Of course, full-text search is possible on each document site and constructing searches derived from the Open Calais and Yahoo Term Extraction plugin is also possible as I’ve shown above. Full text search could end up returning more results than are useful. I’ve no strong opinions about this either way.
Finally, you can see in the menu bar on the front page that there’s an ‘About JISCPress’ page and a JISCPress blog. Nothing fancy going on there. We’re just using basic BuddyPress features.
Accessibility
Well, we haven’t ignored accessibility requirements but then again, they haven’t been a driving factor in the development of JISCPress either. I think we’ve improved on CommentPress and have had useful feedback from the British Computer Association for the Blind on the accessibility of digress.it. At one point Eddie included the jQuery.accessible plugin in digress.it but it’s not currently being used. Along similar lines, much time was spent on IE6 compatibility, which has been achieved at some cost to the project. The user experience in IE6 is not as nice as using Chrome, for example, and I wonder whether it was worth the effort in a project such as this that was about producing a ‘prototype demonstrator’. Nevertheless, because digress.it is now in widespread use elsewhere, IE 6 & 7 compatibility was one of the first requests that came through on the mailing list. We did a quick survey of browser use in HEIs and Andy Powell followed this up with something more detailed and wide ranging. What both show is IE 6 & 7 can’t be ignored 🙁
I feel that we didn’t manage to do as much toward accessibility as I originally hoped but it is something that can be worked on with digress.it over time and I know it is something that interests Eddie a great deal. Hopefully as he does work for more organisations, like Cornell and the New York Public Library, their accessibility requirements will filter through into the core code. In addition, Eddie has recently been able to employ a designer to work with him on digress.it so the theme should get more close attention over the next few releases.
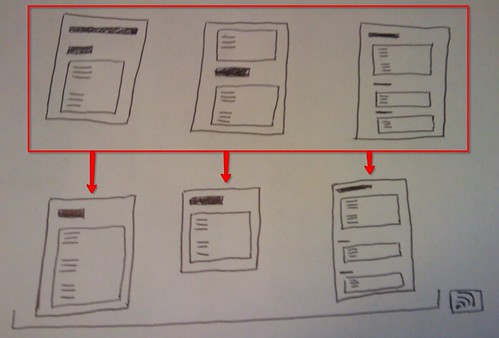
Related content utilities
Alex did a lot of work on this and has released his wpmu-related-blogs-and-posts plugin on the official WordPress plugin repository.
Here’s an overview:
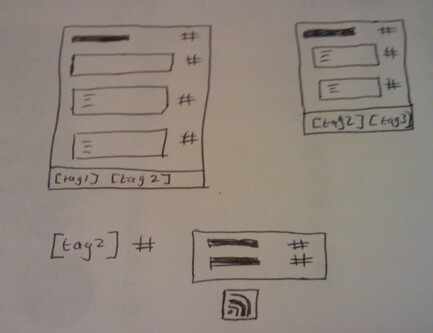
The WPMU Site Admin options look like this (click the image to see it full size):

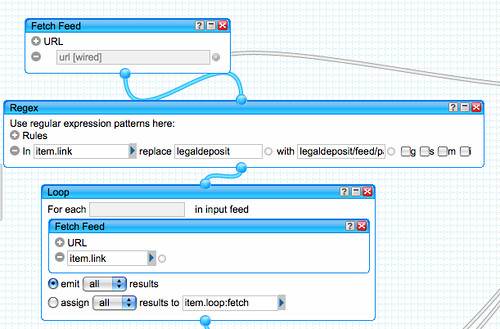
You can see that both or either the Open Calais and Yahoo Term Extraction APIs can be used. The plugin provides a background service which runs via a cron job, which can be set to daily, twice daily or hourly. The cron job can be started manually and the entire platform can be re-tagged at any time. The relationships between document sections and documents can be re-established at any time, too.
Both the relevance of the tags (using features of the APIs) and the relevancy of the posts (when showing related document sections), can be adjusted.
Finally, you can opt to ignore certain blogs/documents, so test sites and the main site don’t mess up the weighting of the relationships made.
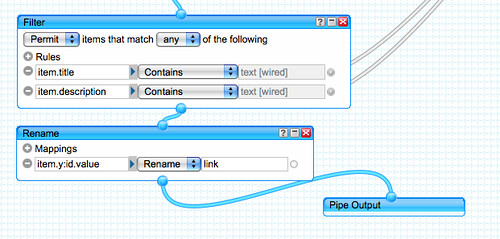
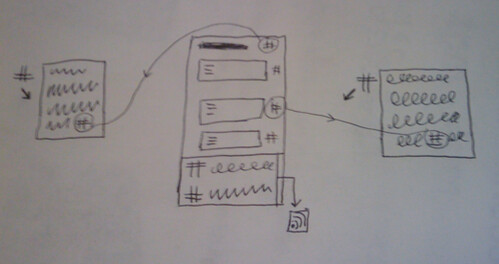
As we’ve seen with the JISCPress Browser widget, those tags can be used to provide a way to navigate the entire platform. However, the principle intended use of the Open Calais/Yahoo services is to display related document sections or, optionally, related documents while reading any given document. One potential issue with the auto-tagging services relates to the variable quality and usefulness of the tags they return. One possible way of addressing this would be to limit the range of tags used on the site by filtering the automatically generated tags via a whitelist, blacklist, or based on semantics (e.g. ignore placenames).
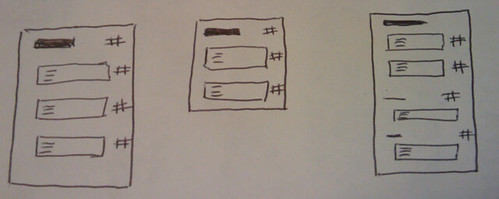
Here’s the widget options:

Here’s the widget as displayed to the reader. In principle, it works and should work better as the number of documents on the site grows.
Related documents/blogs:

Related document sections/blog posts:

Realtime messaging
This deliverable has been tackled in two ways. Eddie developed realtime alerts for digress.it so that if someone comments on the site while you’re reading it, the comment will ‘pulse’ in the Comment Box. For remote realtime messaging, things have been taken care for us. As realtime on the web is becoming very much mainstream, it’s getting easier to push content out through a variety of ways. For example, since the start of our project, WordPress now has RSSCloud and Web Hooks plugins. The latter provides a relatively simple framework for developers to push any notification from WordPress to external services, as I’ve discussed on my blog. There are also SUP (FriendFeed) and PubSubHubbub plugins, too. In addition, Google is now indexing in realtime and Google Alerts are showing up via RSS almost immediately, too. XMPP PubSub is also in use on WordPress.com and that work is due to be released as plugin for WordPress once it has been well tested. Likewise, their work on a Twitter compatible API for WordPress will also be released. Given all of this, we didn’t think we needed to reinvent the realtime wheel for WordPress.
Authentication Services
I can confirm that LDAP works well with WPMU. I know this because I run WPMU with this plugin at the University of Lincoln. It is a feature rich plugin and well supported. If anyone wants to integrate LDAP with WPMU and is running into problems, please get in touch. Note that there is no reason why much of JISCPress couldn’t be used as a private platform for document discussion and annotation, internal to an organisation.
Shibboleth support was not tested because we don’t use it at Lincoln and I never got around to trying to convince someone to help me test it. However, I have been told by the plugin developer that it is in use at other universities and it too, is well supported by Will Norris, the developer of the WordPress Open ID plugin. I would be very grateful if someone running a Shibboleth service at their institution would help me test the plugin. I’m pretty confident that it will work.
Open Calais
See above!
Amazon Web Services
I documented our use of Amazon Web Services on our Google Code site. I had intended to leave an image of the JISCPress server on AWS so that anyone could clone it for use or play. However, unless asked, I’m not going to do that now. If you want to use such a system, you can use http://digress.it or http://writetoreply.org or and if you’re skilled enough to work on AWS, then you’re skilled enough to install WPMU and our plugins on your own server for testing purposes. I’d be happy to advise anyone wanting to create their own version of JISCPress and even work on your server if you want me to. Leaving an Amazon Machine Image lying around for testing means that it will soon go out of date as new versions of WordPress are released and need rebuilding anyway.
Workflow for authors
I have begun writing documentation for authors on our Google Code site. I’d be grateful for feedback. This documentation is also used on the http://digress.it site. I also intend to provide documentation for Administrators, too. Although if you are running WPMU, then you will be familiar with much of what you need to know. One of the great things about this project is that we’re using one of the most popular pieces of publishing software on the web and there is already a lot of familiarity with it.
Data extraction and syndication
A lot of work went into developing digress.it with this in mind and Alex has also developed a plugin that posts RDF triples to the Talis Platform from WPMU. I’ll say more about that below, but here’s a post I wrote recently about JISCPress and Open Data. I hope you’ll agree that we’ve made good progress in this area.
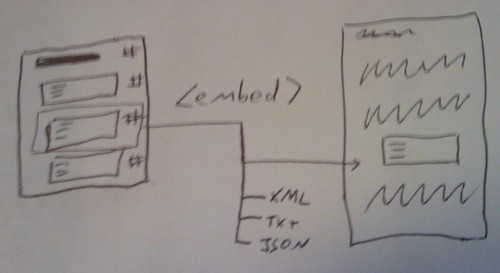
A demonstration of how paragraph level content from JISCPress can be transcluded (that is, embedded) on a third party site is available here: Paragraph Embedding from JISCPress. The post includes a Javascript snippet that can pull in a random paragraph from a contiguous set of paragraphs on a single JISCPress page. Such a utility might be used to rotate through headline pargraphs on a JISCPress document fron page, for example.
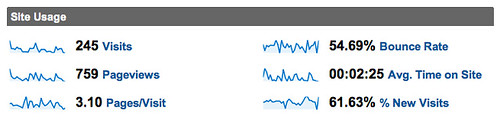
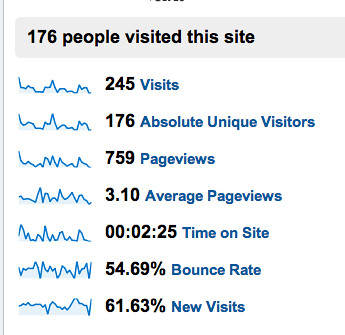
On the subject of web analytics, we reviewed how to collect JICWEBS recommended metrics using Google Analytics (Measuring Website Usage With Google Analytics, Part I , how to monitor traffic coming in from University networks, and how to exploit Google Analytics campaign tracking codes from shared links and via Feedburner. We did intend to look at Piwik, too, as we’ve tinkered with it on WriteToReply, but I’m afraid it didn’t happen. I do want to highlight Piwik to anyone interested in open source analytics software. It allows you to expose the analytics for any given site to the public and provides a number of ways to access the data, via CSV, JSON, XML, RSS. Have a play around on the WriteToReply site to see what I mean. Naturally, there is a WordPress plugin for Piwik, too. Google Analytics has also recently opened up an API that would support the development of custom reporting dashboards. Steph Gray at Helpful Technology has recently described an “ultimate dashboard” built around free tracking/monitoring services – Minding the shop – and is willing to share the code. Such a dashboard could be used to provide a useful overview of document related discussion on the wider web.
Documented user stories
This is an area where I wonder how we might have improved things. As I’ve written about before, the project team has worked virtually, hardly ever meeting and we worked very much in public, with digress.it having a fairly broad range of users mid-way into the project. For some of our work, we were not short of user feedback but for other areas, we received hardly any. I set up a UserVoice site early on and we’ve asked people to use it and linked to it from our blog, but it’s never seen any use. Feedback on the project in general has been quite low, although we receive informal feedback on how WriteToReply might be improved quite regularly and similarly, there has been a lot of feedback on digress.it over Twitter.
I have tried to document some of the uses of JISCPress that I could think of. They’re not really User Stories or even complete scenarios, but it does sketch out some of the uses that I could think of and I’ll add to them as I think of them. It will be interesting to demonstrate JISCPress to JISC and be able to respond to their feedback now we have a working platform. JISC staff have started using digress.it on WriteToReply (the #jisclms Call was re-published by two JISC staff) and I anticipate there being more opportunities for us to work with JISC staff on using some of the work we’ve done in the near future.
Other work
I mentioned the work that Alex has done on connecting WPMU to the Talis Platform. Using Triplify, he’s developed a plugin that runs a service which posts RDF Linked Data to Talis. It can be downloaded from the WordPress repository.
The plugin has some global options, available to the platform admin, which are pretty self-explanatory (click to enlarge)

Each site owner also has the option to participate, too. First you agree:

and then you set your license:

The RDF data is available at both the http://example.jiscpress.org/triplify endpoint and for query on Talis. This is what you get back, for example:

The configuration file for WPMU is available here. Be sure to check it over to ensure that it exposes the data you want it to expose and no more! Also, do read the Triplify documentation. You’ll see that it does more than produce RDF. There’s JSON output, too.
Final reflections
These final reflections are from Joss.
I’m pretty pleased with the way the project has gone. It’s been a real pleasure to work on the project and to work with Tony, Eddie and Alex. Not once have I felt it a chore even at some of the ridiculous hours of the night that we’ve worked. I’m also very grateful to JISC for thinking that it was a project worth funding and the support from JISC in terms of the JISCRI conference/IE Demonstrator and general lack of interference, but steady encouragement, has been really welcome, too.
I think we’ve delivered enough of the original objectives to have made it all worthwhile. There are areas, such as accessibility and more user testing, which I wish we’d been able to do better, but it wasn’t for want of trying. I really wish we’d cracked simple embedding of paragraphs and paragraph-level trackbacks, too. We’re close, but not quite there, yet.
On the other hand, we have produced some pretty nice plugins for WordPress. For WordPress developers, digress.it provides some significant innovations around document publishing and Open Data in WordPress and the code is free to be built on and improved. Likewise, we’ve also produced the first plugin that allows WPMU admins to run a background service for Open Calais and Yahoo Term Extraction across all blogs/documents. Another ‘first’ for the project, is that we’ve joined WPMU to Triplify and the Talis Platform. Huge amounts of data are generated by WPMU installations and now that can be Linked Data hosted on a well known Data Store. It would not be difficult to bring both plugins together so that the Open Calais semantic tags are included as data that is posted to the Talis Platform.
The legacy of the project will hopefully be similar to what we’re trying to achieve with WriteToReply. Not necessarily a wholesale conversion of organisations to using the platform with all its features that I’ve described above, but for people to pick and choose what works best for them. It may be that the project just inspires something better or different on another platform, like Drupal, and that’s good, too. It’s also about trying to demonstrate how publishing and engagement with public documents on the web can still, very much, be improved. In that sense, there is probably as much value in the blog posts that our work has generated as the software itself. We’ll continue to write about this on the WriteToReply blog.
All the code is open source and available under the GPL (digress.it) or Modified BSD license (Calais and Talis plugins). Eddie continues to maintain digress.it and I know that Alex is keen to ensure that any issues identified with his code are dealt with too. If you use the code and improve it in anyway, do tell us as we’re keen to include contributions from other developers.















































 .
.